
HandNeRF—建模位置驱动的交互双手
Published:
一篇专注于交互双手的Nerf工作。

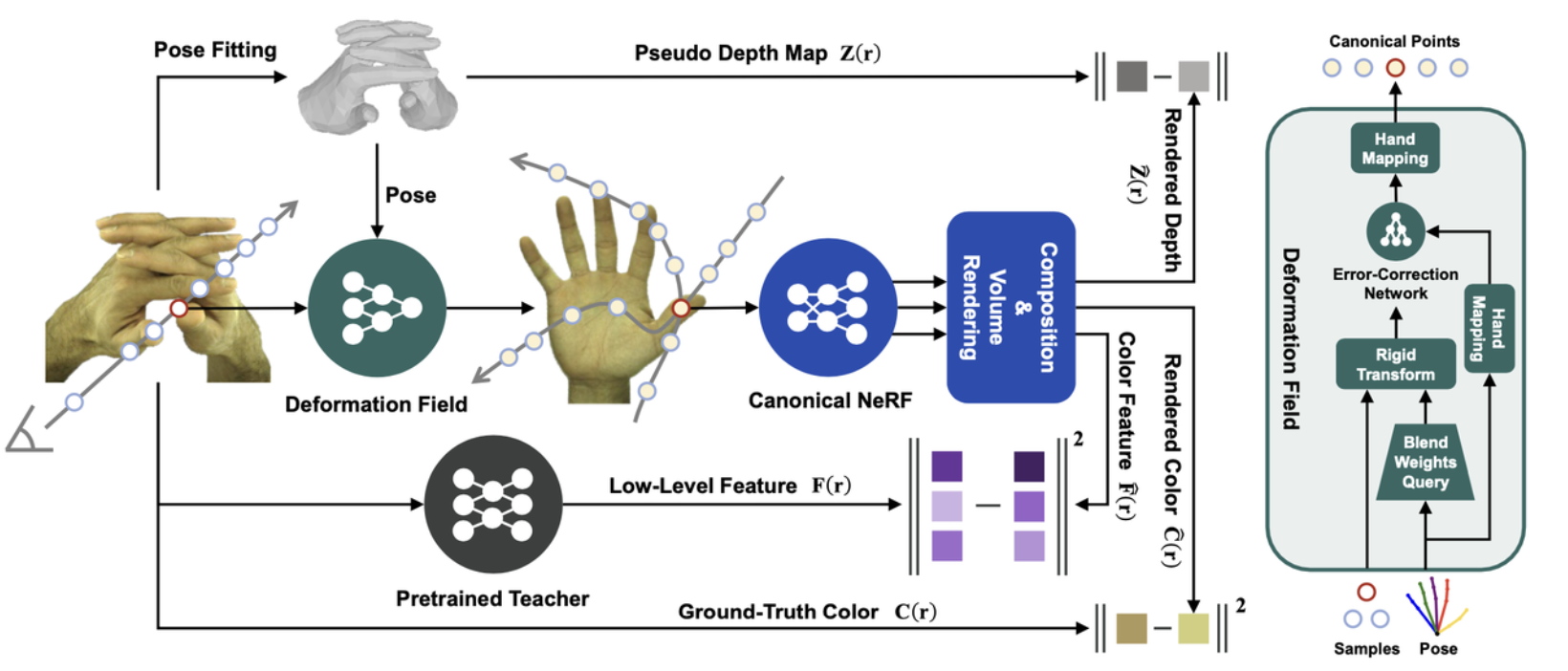
传统的NeRF由于是在静态的场景下进行优化,因此其缺少建模不同姿势的双手的能力;因此作者这里引入了一个受姿势控制的变形场,这个变形场可以将在双手中采样到的射线通过变形传递到一个共享的空间(共享空间中有个为标准手建模的静态NeRF)中。
- 规范手部表示
在实际应用中,观察者可能在不同的尺度上观察手部,因此模型需要能够处理不同尺度的观察,HandNeRF采用了类似于Mip-NeRF的锥形追踪架构。Mip-NeRF是NeRF的一个变体,它通过使用多尺度的圆锥形采样来改善渲染质量和效率。具体来说,分别采用了两个MLP来进行密度$\sigma$和颜色$\mathbf{c}$的估计:
\[\begin{aligned}&\sigma=F_{\boldsymbol{\Theta}_\sigma}\left(\mathrm{IPE}\left(\mathbf{x}_{can},\boldsymbol{\Sigma}\right)\right)=F_{\boldsymbol{\Theta}_\sigma}\left(\mathbf{f}_\sigma\right),\\&\mathbf{c}=F_{\boldsymbol{\Theta}_c}\left(\mathrm{PE}\left(\mathbf{d}\right),\mathbf{f}_\sigma,\ell_c\right),\end{aligned}\]其中 $ \boldsymbol{\Sigma} $ 指的是样本点 $\mathbf{x}$ 的多尺度表示,是与 $\mathbf{x}$ 相关联的特征矩阵,而 $\mathbf{d}$ 是观察的方向,$\ell_c$ 是用于捕捉不同帧之间细微的纹理变化的潜在代码,是模型的一个可训练参数;其中的 $\mathrm{IPE}$ 是指积分位置编码是Mip-NeRF中提出的一种编码方式,其通过积分操作来计算每个采样点的位置编码,从而减少由于采样点间隔导致的渲染不连贯性,$\mathrm{PE}$ 指的是位置编码。
- 变形场
给定任意的手部姿势,变形场学习从该观察空间到所有姿势手共享的规范空间的映射。
如果没有任何的位置先验,去建模这种位置的变换是十分困难的;因此作者使用了在MANO之间的典型设置(16个手部节点等,权重为16维等):跟很多经典的基于mesh的方法一样,MANO使用线性蒙皮(Linear Blend Skinning,它允许模型的顶点位置根据一组骨骼(关节)的运动进行变形)来完成网格点的曲线驱动变形。它将不同姿势之间的坐标变换建模为通过混合蒙皮权重加权的关节刚性变换的累积。
HandNeRF直接将这样的骨架驱动的变换作为变形场的强先验,对于观测空间中给定的位姿\(p\)和一个3d样本$x_{ob}$,获得已摆好姿势的MANO网格并查询距离$x_{ob}$最近的网格面,这里查询到的混合蒙皮权重可以通过重心插值相对应的面顶点上进行计算获得,最终这个大致的变换可以被表示为:
\[\hat{\mathbf{x}}_{can}=T\left(\mathbf{x}_{ob},\mathbf{p}\right)=(\sum_{j=1}^{16}w_{bj}\mathbf{T}_j)\mathbf{x}_{ob}\]其中的$\sum_{j=1}^{16}w_b=\begin{bmatrix}w_{b1},\ldots,w_{b16}\end{bmatrix}$指的是距离$x_{ob}$最近的网格面的混合权重,所以$\mathbf{T}_{j}$视为骨骼模型中每个关节的固定参数,这些参数定义了关节在空间中的位置和方向,所以能代表第$j$个关节从观测空间到规范空间的变换。
为了避免插值和参数化模型本身不可避免造成的误差,作者还引入了一个额外的姿势条件误差校正网络$F_{\Theta e}$,最终在规范空间的表达为:
\[\mathbf{x}_{can}=\psi\left(\hat{\mathbf{x}}_{can}+F_{\boldsymbol{\Theta}_e}\left(\psi\left(\hat{\mathbf{x}}_{can}\right),\psi\left(\mathbf{p}\right)\right)\right).\]$F_{\Theta e}$的作用是对$\hat{x}_{can}$进行进一步的非线性校正,$\psi(\cdot)$是一个是一个手部映射函数,用于将左手和右手的坐标对齐到一个统一的典型空间中。
- 采样和合成策略
利用采样的信息,可以轻松估计一个参数化的手部网格模型从而得到3D空间和2D图像的粗略场景边界。然后可以将2D的图像边界作为前景掩码的伪标签,用于指导像素(射线)采样。对于高分辨率的训练图像,作者选择只在1%的像素上执行光线追踪,使得更多的注意力被放在目标手部的纹理上,并且显著加快了训练速度;以及3D场景边界帮助确定摄像机射线的近远边界,在这个范围内均匀地选择$N$个3D样本。
深度引导的密度估计
传统NeRF在训练视图不足时容易出现视觉过拟合,即尽管从特定相机视角渲染的图像看起来颜色效果不错,但实际上场景的几何结构(密度)并没有被正确提取。这种过拟合导致的问题在于,虽然在训练视图上看起来不错,但在新的视角下进行合成时,渲染效果会急剧下降。为了解决这个问题,HandNeRF引入了2D深度监督来优化3D密度估计。以往的工作大多通过利用SFM预处理生成稀疏的3D点云作为深度标签,而HandNeRF则利用了在前文中提到的参数化手部模型,这样以更低的成本获得深度信息。一旦得到特定姿势的整个手部网格模型,在特定视角下每个像素点处的深度值也同时得到,利用这个深度信息,HandNeRF构建了一个伪深度图,作为训练视图的深度真值$Z(\mathbf{r})$;而NeRF估计的像素级深度可以通过经典的体积渲染公式得到:
\[\hat{Z}(\mathbf{r})=\sum_{i=1}^NT_i\left(1-\exp\left(-\sigma_i\delta_i\right)\right)t_i,\]而HandNeRF的目标是最小化NeRF估计的深度$\hat{Z}(\mathbf{r})$和目标深度图$Z(\mathbf{r})$之间的差异,这里作者选择使用像素级平滑L1距离进行正则化,是因为基于网格的伪深度自然保持了表面一致性。
特征蒸馏模块
在传统的NeRF训练中,多视图训练图像仅用于独立的像素级监督。这种方法可能导致在特定视图中手部可见区域较小时模型陷入局部最优,并且在新的视图或姿势上出现伪影和模糊。
为了解决这些问题,HandNeRF采用了特征蒸馏,其核心目标是将预训练的2D提取器产生的2D图像特征与3D空间中定义的相应样本特征对齐,这样,由于特征提取器的感受野,可以隐式地将上下文线索引入颜色场的优化,这里作者采用了一种跨域学生-教师范式的特征蒸馏方法。在这个范式中,2D教师网络的特征被蒸馏到3D学生网络中。具体来说,作者使用NeRF来生成颜色特征和密度特征 $\mathbf{f} $ (因为在公式中 $\mathbf{f}$ 也是中间量),然后使用体渲染公式对所有沿着射线的样本的 $\mathbf{f}{c}$ 进行积分,最终得以生成预测的像素特征 $\mathbf{\hat{F}}(\mathbf{r})$ ;目标图像特征是从使用公开可用权重预训练的DINO的第二层提取的,目的是专注于纹理细节而非高级语义。然后,该特征通过L2归一化,并使用PCA降至D维,以产生目标像素特征 $\mathbf{F}{r}$ 。
通过特征蒸馏,HandNeRF能够利用2D教师网络学习到的丰富特征信息,来指导3D颜色场的学习,这不仅提高了渲染图像的质量,还增强了模型对新视角和新姿势的泛化能力。
损失函数设计
HandNeRF最终的损失函数设计为:
\[\begin{aligned}\mathcal{L}=&\mathcal{L}_{rgb}+\lambda_{depth}\mathcal{L}_{depth}+\lambda_{dst}\mathcal{L}_{dst}+\\&\lambda_{dfm}\mathcal{L}_{dfm}+\lambda_{hs}\mathcal{L}_{hs}+\lambda_{cvar}\mathcal{L}_{cvar}\end{aligned}\]其中 $L_{rgb}$ 是初始NeRF中使用的合成颜色与颜色真值的损失;$L_{depth}$是估计深度与手部网格真值模型的差距损失(像素级平滑L1距离), $L_{dst}$ 是特征蒸馏模块中老师网络与学生网络产生的特征之间损失; $L_{dfm}$ 则是在姿势条件误差校正网络 $F_{\Theta e}$ 的输入中中为每个样本$x$的纠错项添加一个正则化器,以便非线性变形很小(增加泛化性);$L_{hs}$ 则是使得体渲染中每个样本的权重尽量为1或0(减轻半透明几何形状和目标手周围的雾光晕); $L_{cvar}$ 是作者新提出的颜色方差损失,是的所有样本最后的颜色更为接近(重建的手部往往颜色相对单一)。
新的姿势的产生与泛化
由于HandNeRF设计了完全可操作的姿势输入,因此可以很轻松地实现动态的交叉手渲染,以及网格的先验和规范手部模型确保了新的姿势的可行性;此外,整个框架可以被修改为用于姿态适应的微调管道,具体来说是冻结特征蒸馏模块和NeRF模块的权重,微调变形场即可实现新的姿势的产生。
参考资料
Guo Z, Zhou W, Wang M, et al. HandNeRF: Neural radiance fields for animatable interacting hands[C]//> Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 21078-21087.
```