
Pytorch进阶之那些基础但重要的知识点二
Published:
因为我在深度学习的上机中对于“冻结权重”这个相对常见的操作感到一脸懵逼,这还是在提醒我自己的torch并不熟练。
当时的一个操作是这样的,在前50个batch中将原始网络中backbone中的权重去冻结,在后面100个batch中将权重去解冻,这样的话即加快了收敛,也省了很多事情。
# 请将classes_path指向数据集对应的类别
classes_path='model data/Helmet classes.txt'
#请在此冻结主干特征提取网络部分的参数
for param in model.backbone.parameters():
param.requires grad =False
#当前epoch已经大于冻结学习的代数,请在此对主干特征提取网络解冻
for param in model.backbone.parameters():
param.requires grad = True
torch.nn.parameter
torch.nn.parameter是torch中一种特殊类型的tensor,用于表示神经网络中的可学习参数,for example,全连接层中的torch.nn.Linear()中的参数weight和bias。
与torch.tensor的区别
是否会自动添加到模型的参数列表中
- 使用
torch.nn.parameter定义的张量可以被自动的添加到模型的参数列表中,并且可以通过.parameters()的方法或者.name_parameters()的方法列出
import torch
import torch.nn as nn
class Layer(nn.Module):
def __init__(self):
super().__init__()
self.weight = torch.nn.Parameter(torch.tensor([1.,2.]))
def forward(self,input):
return input * self.weight
layer = Layer()
print(layer.weight.requires_grad)
for name,param in layer.named_parameters():
print(name) # weight
print(param)
输出结果为:
True
weight
Parameter containing:
tensor([1., 2.], requires_grad=True)
- 而普通的
torch.tensor对象是不会被自动的添加到模型的参数列表中的,因此也不会被.parameters()的方法或者.name_parameters()的方法给查询到。
import torch
import torch.nn as nn
class Layer(nn.Module):
def __init__(self):
super().__init__()
self.weight = torch.tensor([1.,2.])
def forward(self,input):
return input * self.weight
layer = Layer()
print(layer.weight.requires_grad)
for name,param in layer.named_parameters():
print(name) # weight
print(param) # 无输出,打印不出来任何的结果,说明该参数甚至未被放到参数的列表中去
output:
False
required_grad属性
这一点相对容易理解,也即使用torch.nn.Parameter定义的对象其required_grad属性默认为True,而一个简单的torch.Tensor定义的张量其required_grad属性默认为False。
torch.nn.Parameter定义的对象的属性被设置为True的时候,他们会参与自动的求导,并且可以被优化器自动地更新,这也解释了我们平时设置优化器时候为什么都是optimizer = optim.SGD(mode.)。对于普通的
torch.Tensor对象,即使将其required_grad属性设置为True,也不会被自动的添加到模型的参数中去,也不会被优化器自动更新。
nn.Linear
nn.Linear是我们炼丹时候十分常见且简易一个操作,但是有了上面这些知识的先验,我们印象中的nn.Linear应该有所改变,例如,至少我们要明白,其中的weight和bias属性都是通过torch.nn.Parameter封装起来的。
简易版本的pytorch实现
def __init__(self, in_features: int, out_features: int, bias: bool = True,device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))
if bias:
self.bias = Parameter(torch.empty(out_features, **factory_kwargs))
else:
self.register_parameter('bias', None)
self.reset_parameters()
tensor.view & tensor.reshape
发现一篇写的十分详细的,从底层开始剖析的知乎博客
tensor.view & tensor.reshape在实际中的表现为重新组织shape - tensor.view返回的是一个新的视图,数据的共享,有contiguous(连续)的要求 - tensor.reshape更加的鲁棒,没有contiguous的要求
- 什么叫contiguous
例如这个2维度的数组arr = np.arrange(12).reshape(3,4) 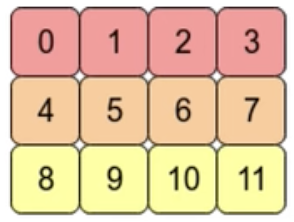 在计算机的内存中,他其实是这样的存储的
在计算机的内存中,他其实是这样的存储的  ,这就是“contiguous”
,这就是“contiguous”
torch.nn.Embedding
‘我一直对Embedding有一层抽象的,模糊的认识’
embedding的基础概念
embedding是将词向量中的词映射为固定长度的词向量的技术,可以将one_hot出来的高维度的稀疏的向量转化成低维的连续的向量
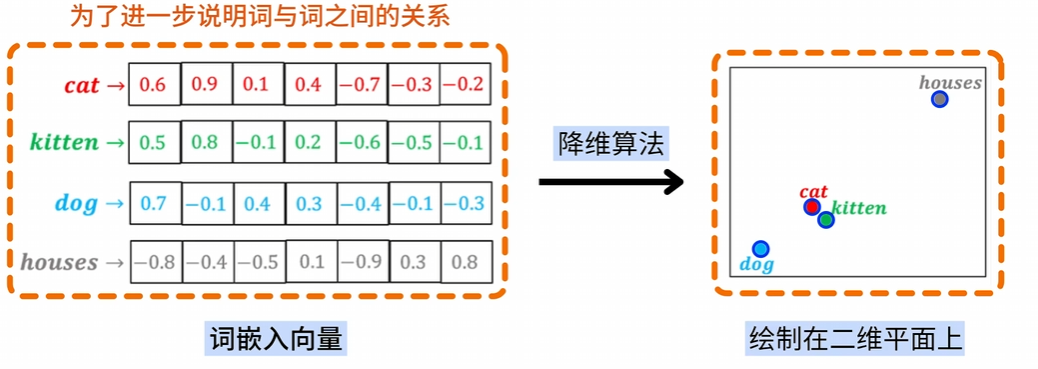
首先明白embedding的计算过程
- embedding module 的前向过程是一个索引(查表)的过程
- 表的形式是一个matrix (也即 embedding.weight,learnabel parameters)
- matrix.shape:(v,h)
- v:vocabulary size
- h:hidden dimension
- matrix.shape:(v,h)
- 具体的索引的过程,是通过onehot+矩阵乘法的形式实现的
- input.shape:(b,s)
- b: batch size
- s: seq len
- embedding(input)=>(b,s,h)
- 这其中关键的问题就是(b,s)和(v,h)怎么变成了(b,s,h)
- 表的形式是一个matrix (也即 embedding.weight,learnabel parameters)
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])
# >>> # example with padding_idx
# >>> embedding = nn.Embedding(10, 3, padding_idx=0)
# >>> input = torch.LongTensor([[0, 2, 0, 5]])
# >>> embedding(input)
# tensor([[[ 0.0000, 0.0000, 0.0000],
# [ 0.1535, -2.0309, 0.9315],
# [ 0.0000, 0.0000, 0.0000],
# [-0.1655, 0.9897, 0.0635]]])
One-Hot 矩阵乘法
目前one_hot可以很方便地在torch.nn.functional中进行调用,对于一个[batchsize,seqlength]的tensor,one_hot向量可以十分方便的将其转化为[batchsize,seqlength,numclasses],此时,再与[numclasses,h]进行相乘,从而得到最终的[b,s,v]
参数padding_idx
这个参数的作用是指定某个位置的梯度不进行更新,但是为什么不进行更新,以及在哪个位置不进行更新我还没搞明白….
>>> # example with padding_idx
>>> embedding = nn.Embedding(10, 3, padding_idx=0)
>>> input = torch.LongTensor([[0, 2, 0, 5]])
>>> embedding(input)
tensor([[[ 0.0000, 0.0000, 0.0000],
[ 0.1535, -2.0309, 0.9315],
[ 0.0000, 0.0000, 0.0000],
[-0.1655, 0.9897, 0.0635]]])
>>> # example of changing `pad` vector
>>> padding_idx = 0
>>> embedding = nn.Embedding(3, 3, padding_idx=padding_idx)
>>> embedding.weight
Parameter containing:
tensor([[ 0.0000, 0.0000, 0.0000],
[-0.7895, -0.7089, -0.0364],
[ 0.6778, 0.5803, 0.2678]], requires_grad=True)
>>> with torch.no_grad():
... embedding.weight[padding_idx] = torch.ones(3)
>>> embedding.weight
Parameter containing:
tensor([[ 1.0000, 1.0000, 1.0000],
[-0.7895, -0.7089, -0.0364],
[ 0.6778, 0.5803, 0.2678]], requires_grad=True)
关于max_norm
这个参数用于设置输出和权重参数是否经过了正则化。