
LLM入门1之阅读综述论文
Published:
这篇博客介绍了我在阅读论文Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond时的笔记
初识LLM之LLM综述
参考论文地址https://arxiv.org/abs/2304.13712
名词解释
- NLU: natural language understanding
- 自然语言理解(Natural Language Understanding, NLU)是所有支持机器理解文本内容的方法模型或任务的总称。NLU在文本信息处理处理系统中扮演着非常重要的角色,是推荐、问答、搜索等系统的必备模块。本文介绍了NLU和NLP、NLG的关系,并基于数据流将NLU的内容进行整理,最后对文本分类、文本聚类和NER这3种典型任务的目标和思路进行了简单说明。(百度百科)
- AGI:Artificial General Intelligence
- 也即通用型的人工智能,亦被称为强 AI,该术语指的是在任何你可以想象的人类的专业领域内,具备相当于人类智慧程度的AI,一个AGI可以执行任何人类可以完成的智力任务。
当前先进的LLM模型
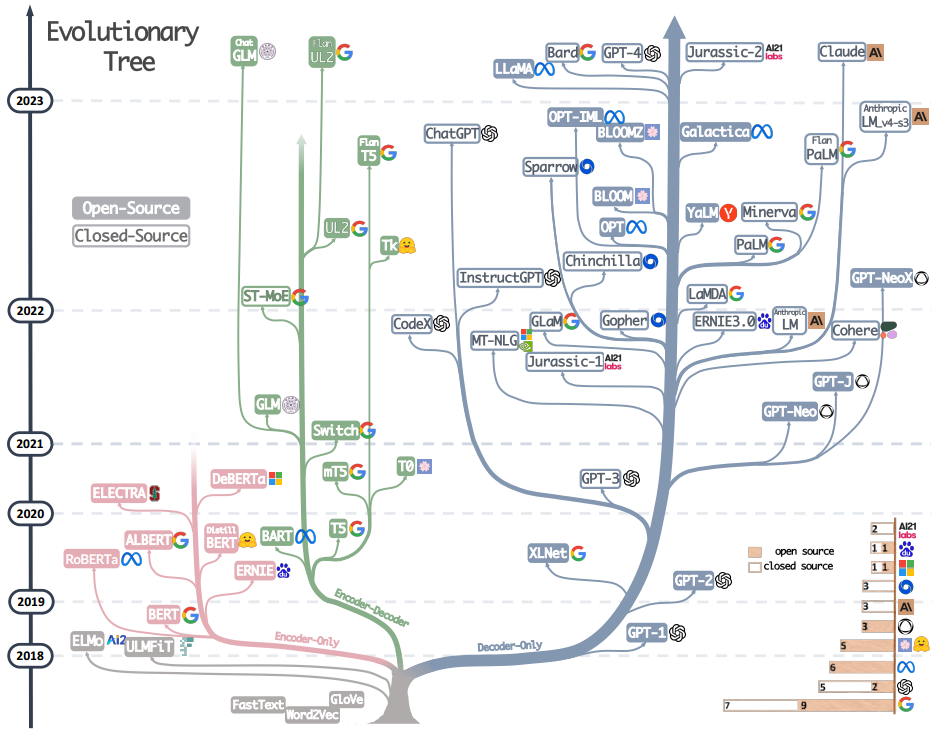 在图中,只有灰色的模型不是基于Transformer结构,其他的模型都是基于Transformer结构;而粉色的branch是表示只有encoder的结构;蓝色的是只有decoder的结构;绿色的是encoder-decoder结合的结构
在图中,只有灰色的模型不是基于Transformer结构,其他的模型都是基于Transformer结构;而粉色的branch是表示只有encoder的结构;蓝色的是只有decoder的结构;绿色的是encoder-decoder结合的结构
- 也即通用型的人工智能,亦被称为强 AI,该术语指的是在任何你可以想象的人类的专业领域内,具备相当于人类智慧程度的AI,一个AGI可以执行任何人类可以完成的智力任务。
可以从图中得到的几个结论
- openai是最牛*的,GPT4和GPT3牛!!!
- Meta提供了最多的开源的llm模型
- 随着GPT-3的提出,越来越多的LLM选择了closed source
- 当前发展最繁盛的是仅有解码器的结构,同时编码器和解码器结合的结构也很有前景(谷歌为其开源做出了巨大的贡献,然而不如多搞搞仅有encoder的结构)
两种style的大模型
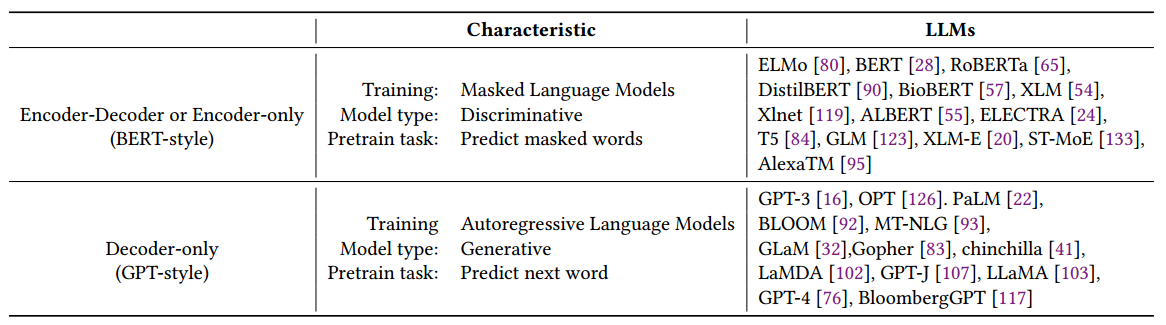
BERT-style:Encoder-Decoder or Encoder-only
无监督的学习很适用于当前计算机的主流,其中一种为在考虑周围环境的同时预测句子中出现的掩蔽词,这种方式为Masked Language Model(NLM)掩蔽语言模型(据说可以提高对与单词的理解和上下文的关系),这类模型一般在大型的文本语料库中进行训练,并在许多的NLP任务上刷了很高的指标,例如BERT,RoBERTa(不过MLM到底是什么还有疑惑)
GPT-style:Decoder-only
针对一个普适的模型,一般是与特定的任务是无关的,但是在面临特定的任务时,微调还是避免不了;如果我们可以扩大语言模型的规模,那么微调可以越来越“微”,甚至做到零样本,其中自回归语言模型(Autoregressive Language Models)这一特性最为明显;这些模型广泛地应用于文本生成和问答等下游的任务。
GPT3是首次通过提示和上下文学习达到了零样本性能,极大地展示了这种自回归模型的优越性。而chatgpt是基于其的改进,使其更符合现实中的应用。
实际应用的问题
是微调模型还是大语言模型
如果可以找到跟测试数据比较相似的训练数据,那么微调的模型是更好的,但是如果没有,甚至是对抗任务或者领域迁移这种情况,大模型是更diao的
预训练数据
预训练数据Pre-trained data是最为关键的;常用的预训练数据由无数的文本源组成,包括书籍、文章和网站。这些数据经过精心策划,以确保全面反映人类知识、语言细微差别和文化观点。预训练数据的重要性在于它能够为语言模型提供对单词知识、语法、语法和语义的丰富理解,以及识别上下文和生成连贯响应的能力。
Finetuning data
在考虑为下游任务部署模型时候,考虑的有三个场景“0”,“少量”,“丰富”
没有标记数据的情况
也即零样本的情况,这种情况下使用LLM被证明是最为有效的
很少标记数据的情况
将少数的标记数据直接的纳入到LLM的输入提示中,上下文学习;这样可以有效的引导LLM到其对应的任务中去,个人感觉这个跟(小样本学习)的概念是一样的
标记的数据十分丰富的情况
这种时候就使用微调模型了