
Diffusion入门知识3—初识扩散模型
Published:
在推导完VAE之后,我们有信心对着Diffusion出发了
Diffusion是如何运作的
The sculpture is already complete within the marble block, before l start my work. lt isalready there, I just have to chisel away the superfluous material.
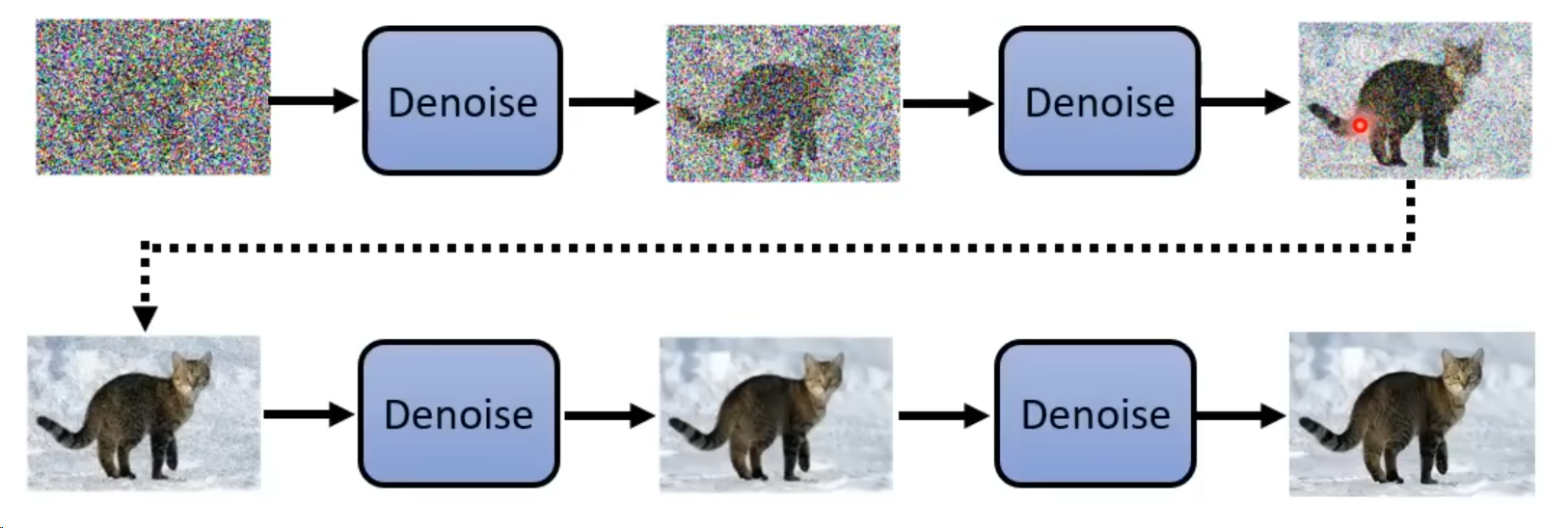
这里Denoise的模块都是同一个,是在被反复地使用,但是这里每次输入的图像差距很大,只使用一个Denoise模块难免会力不从心,因此还有一个step的输入。

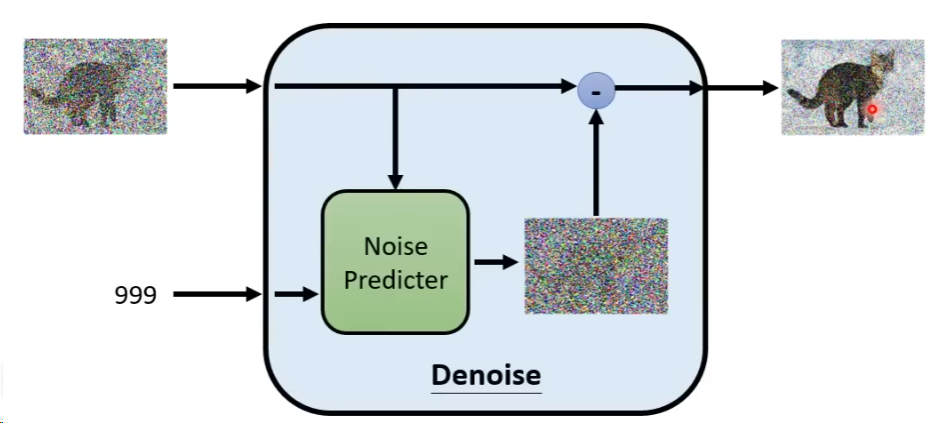
里面的Denoise Predictor用于预测这里面的噪音长什么样子,一个是充满Noise的图片,一个是Noise严重的程度,也就是这里的Steps,Predictor用于预测出噪音,然后将原始的图像减去这里的噪音,得到去噪之后的图像。李宏毅老师说,这样做是相对简单的,比起直接产生一个完整的图像。
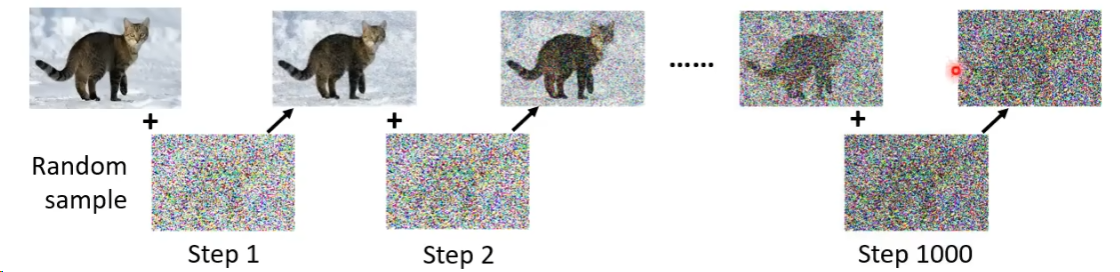
而这种含有噪声的图像是被创造出来,也即自己给干净的图片去加上噪音,这里加上噪声的过程叫做forward Process 也叫做Diffusion Process,经过Diffusion Process之后,就可以训练出Noise Predictor的权重了,而Noise Predictor训练的过程是使用加完噪声的图片和加噪声之前的图片的顺序是什么。
Text to Image
在做Denoise的时候,把文字加入到Denoise的模组中即可: 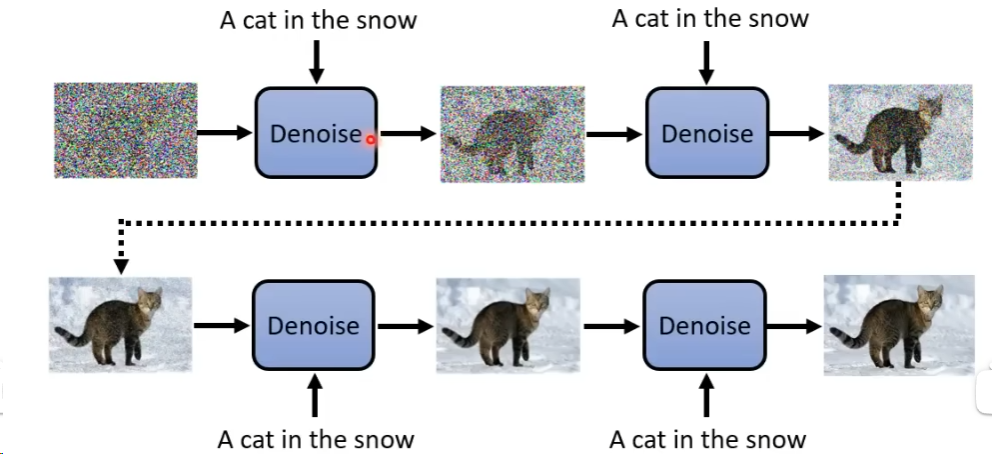 也即直接把这段文字给Noise Predictor就结束了(Noise Predictor的输入是三个,含有噪声的图,step和文字)。
也即直接把这段文字给Noise Predictor就结束了(Noise Predictor的输入是三个,含有噪声的图,step和文字)。
生图的产品
- Stable Diffusion
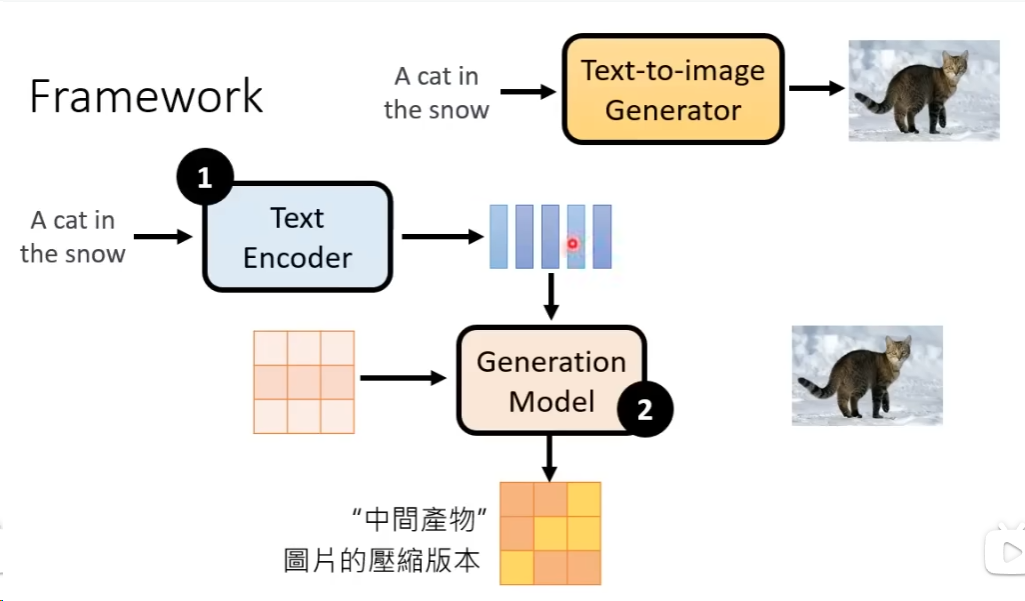
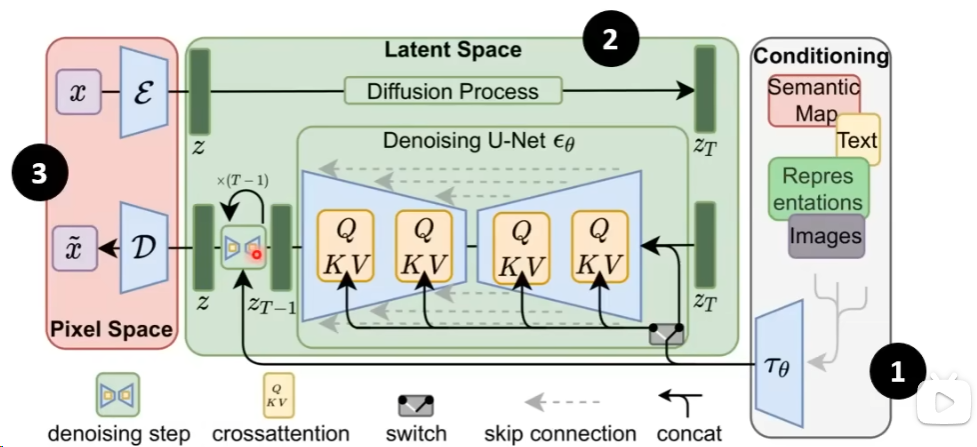
当前最好的图片生成模型,内部基本有3个元件,第一个是Text Encoder 把文字的叙述变成一个一个的向量;第二个是Generation Model,他的输入是一个噪声和文字encoder之后的信号,输出是一个压缩版本的图像;第三是一个Decoder,从一个压缩后的版本还原回原始的图片,通常这三个module是分开训练,然后再组合起来的,
- DALL-E
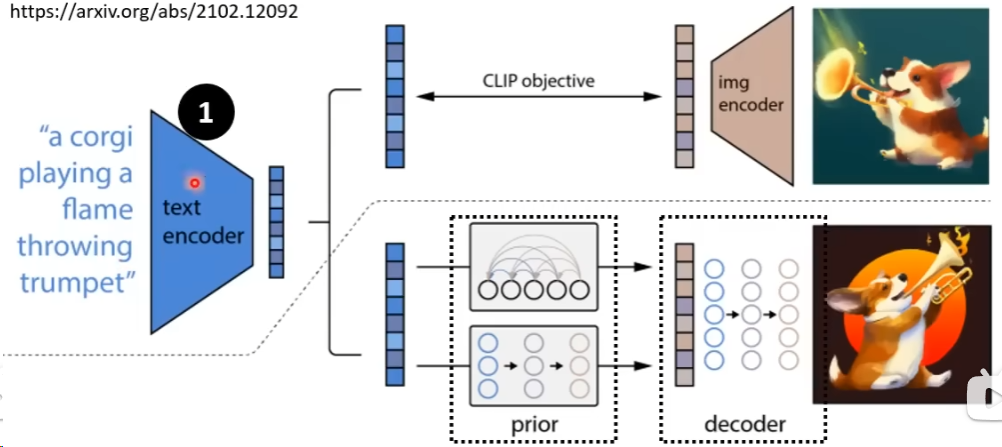
DALL-E的基本架构与Stable Diffusion一致,也是由三个部分组成,
上述三个部分
文字的encoder
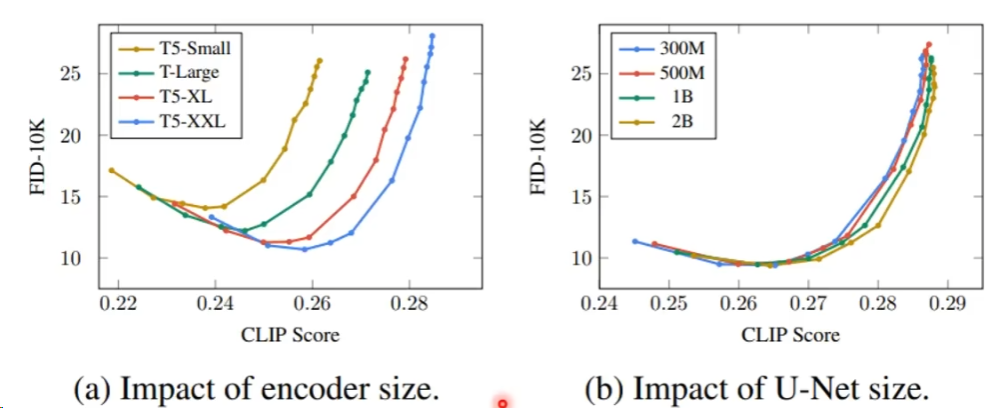
其实就可以采用GPT的encoder,更简单一点甚至可以直接使用的Bert的encoder,而在下图中我们可以看出,相对而言Diffusion model 的参数量的影响是很小的。
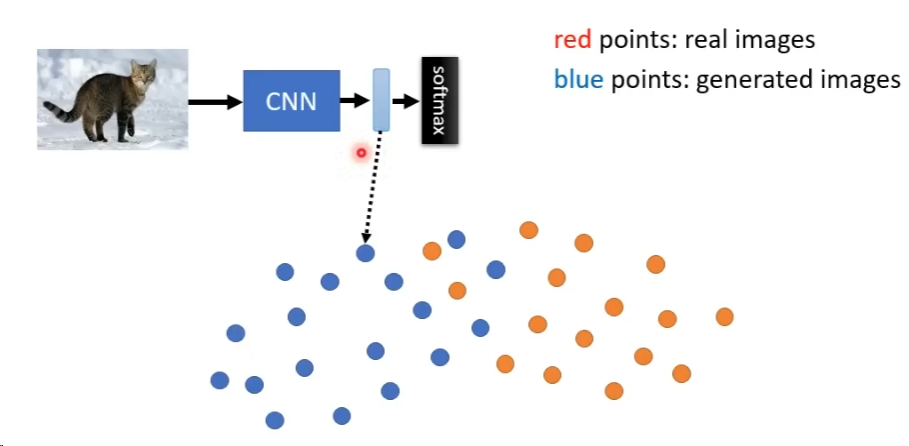
- FID
我们需要一个评价模型生成图质量好坏的标准,简单来说是使用CNN来生成真图像和假图像的特征表示,然后假设这两种图像的特征表示都可以用高斯分布来表示,然后去计算两个高斯分布之间的距离,距离是越小越好。
- CLIP
对比学习,文字和图像是一对的会越来越近,不是一对的会越来越远。
压缩图像的decoder
这里decoder的训练可以是不需要其他额外资料的
- 中间产物为小图

- 中间产物为隐变量/隐表征 latent representation呢
那就是autoencoder的套路